Last week, Warner Bros. issued a DMCA takedown notice
to the video streaming website Vimeo. The notice concerned a pretty
standard list of illegally uploaded files from media properties Warner
owns the copyright to — including episodes of Friends and Pretty Little Liars, as well as two uploads featuring footage from the Ridley Scott movie Blade Runner.
Just a routine example of copyright infringement, right? Not exactly.
Warner Bros. had just made a fascinating mistake. Some of the Blade Runner footage— which Warner has since reinstated — wasn't actually Blade Runner footage. Or, rather, it was, but not in any form the world had ever seen.
Instead, it was part of a unique machine-learned encoding project,
one that had attempted to reconstruct the classic Philip K. Dick android
fable from a pile of disassembled data.
Sample reconstruction from the opening scene of Blade Runner.
In other words: Warner had just DMCA'd an artificial reconstruction
of a film about artificial intelligence being indistinguishable from
humans, because it couldn't distinguish between the simulation and the
real thing.
Deconstructing Blade Runner using artificial intelligence
Terence Broad is a researcher living in London and working on a master's degree in creative computing. His dissertation, "Autoencoding Video Frames,"
sounds straightforwardly boring, until you realize that it's the key to
the weird tangle of remix culture, internet copyright issues, and
artificial intelligence that led Warner Bros. to file its takedown
notice in the first place.
Broad's goal was to apply "deep learning" — a fundamental piece of
artificial intelligence that uses algorithmic machine learning — to
video; he wanted to discover what kinds of creations a rudimentary form
of AI might be able to generate when it was "taught" to understand real
video data.
As a medium, video contains a huge amount of visual information. When
you watch a video on a computer, all that information has usually been
encoded/compressed and then decoded/decompressed to allow a computer to
read files that would otherwise be too big to store on its hard drive.
Normally, video encoding happens through an automated electronic
process using a compression standard developed by humans who decide what
the parameters should be — how much data should be compressed into what
format, and how to package and reduce different kinds of data like
aspect ratio, sound, metadata, and so forth.
Broad wanted to teach an artificial neural network how to achieve
this video encoding process on its own, without relying on the human
factor. An artificial neural network is a machine-built simulacrum of
the functions carried out by the brain and the central nervous system.
It's essentially a mechanical form of artificial intelligence that works
to accomplish complex tasks by doing what a regular central nervous
system does — using its various parts to gather information and
communicate that information to the system as a whole.
Broad hoped that if he was successful, this new way of encoding might
become "a new technique in the production of experimental image and
video." But before that could happen, he had to teach the neural network
how to watch a movie — not like a person would, but like a machine.
Do encoders dream of electric sheep? (Or, how do you "teach" an AI to watch a film?)
Broad decided to use a type of neural network called a convolutional autoencoder. First, he set up what's called a "learned similarity metric" to help the encoder identify Blade Runner
data. The metric had the encoder read data from selected frames of the
film, as well as "false" data, or data that's not part of the film. By
comparing the data from the film to the "outside"data, the encoder "learned" to recognize the similarities among the pieces of data that were actually from Blade Runner. In other words, it now knew what the film "looked" like.
Once it had taught itself to recognize the Blade Runner data,the
encoder reduced each frame of the film to a 200-digit representation of
itself and reconstructed those 200 digits into a new frame intended to
match the original. (Broad chose a small file size, which contributes to
the blurriness of the reconstruction in the images and videos I've
included in this story.) Finally, Broad had the encoder resequence the
reconstructed frames to match the order of the original film.
In addition to Blade Runner, Broad also "taught" his autoencoder to "watch"the rotoscope-animated film A Scanner Darkly.
Both films are adaptations of famed Philip K. Dick sci-fi novels, and
Broad felt they would be especially fitting for the project (more on
that below).
Broad repeated the "learning" process a total of six times for both
films, each time tweaking the algorithm he used to help the machine get
smarter about deciding how to read the assembled data. Here's what
selected frames from Blade Runner looked like to the encoder
after the sixth training. Below we see two columns of before/after
shots. On the left is the original frame; on the right is the encoder's
interpretation of the frame: Autoencoding Video FramesReal and generated samples from the first half of Blade Runner in steps of 4,000 frames, alternating real and constructed images.
During the six training rounds, Broad only used select frames from
the two films. Once he finished the sixth round of training and
fine-tuning, Broad instructed the neural network to reconstruct the
entirety of both films, based on what it had "learned." Here's a glimpse
at how A Scanner Darkly turned out:
Broad told Vox in an email that the neural network's version of
the film was entirely unique, created based on what it "sees" in the
original footage. "In essence, you are seeing the film through
the neural network. So [the reconstruction] is the system's
interpretation of the film (and the other films I put through the
models), based on its limited representational 'understanding.'"
Why Philip K. Dick's work is perfect for this project
Dick was a legendary science fiction writer whose work frequently
combined a focus on social issues with explorations in metaphysics and
the reality of our universe. The many screen adaptations his works have
inspired include Minority Report, Total Recall, The Adjustment Bureau, and the Amazon TV series The Man in the High Castle.
And then there's his famous novel Do Androids Dream of Electric Sheep?, which formed the basis of Blade Runner,
a dystopian sci-fi masterpiece and one of the greatest films ever made.
In the film, Harrison Ford's character Rick Deckard has a job that
involves hunting down and killing "replicants" — an advanced group of
androids that pass for humans in nearly every way. The film's
antagonist, Roy Batty, is one of these replicants, famously played by a
world-weary Rutger Hauer. Batty struggles with his humanity while
fighting to extend his life and defeat Deckard before Deckard "retires
him."
Dick was deeply concerned
with the gap between the "only apparently real" and the "really real."
In his dissertation, Broad said that he felt using two of Dick's works
for his simulation project was only fitting:
[T]here could not be a more apt film to explore these themes [of subjective rationality] with than Blade Runner
(1982)... which was one of the first novels to explore the themes of
arial subjectivity, and which repeatedly depicts eyes, photographs and
other symbols alluding to perception.
The other film chosen to model for this project is A Scanner Darkly
(2006), another adaption of a Philip K. Dick novel (2011 [1977]). This
story also explores themes of the nature of reality, and is particularly
interesting for being reconstructed with a neural network as every
frame of the film has already been reconstructed (hand traced over the
original film) by an animator.
In other words, using Blade Runner had a deeply symbolic
meaning relative to a project involving artificial recreation. "I felt
like the first ever film remade by a neural network had to be Blade Runner,"Broad told Vox.
A copyright conundrum
These complexities and nuances of sci-fi culture and artificial
learning were quite possibly lost on whoever decided to file the
takedown claim for Warner Bros. Perhaps that's why, after Vox contacted
Warner Bros., the company conducted an investigation and reinstated the
two videos it had initially taken down.
Still, Broad noted to Vox that the way he used Blade Runner
in his AI research doesn't exactly constitute a cut-and-dried legal
case: "No one has ever made a video like this before, so I guess there
is no precedent for this and no legal definition of whether these
reconstructed videos are an infringement of copyright."
But whether or not his videos continue to rise above copyright claims, Broad's experiments won't just stop with Blade Runner. On Medium, where he detailed the project, he wrote that he "was astonished at how well the model performed as soon as I started training it on Blade Runner,"
and that he would "certainly be doing more experiments training these
models on more films in future to see what they produce."
The potential for machines to accurately and easily "read" and
recreate video footage opens up exciting possibilities both for
artificial intelligence and video creation. Obviously there's still a
long way to go before Broad's neural network generates earth-shattering
video technology, but we can safely say already — we've seen things you people wouldn't believe.

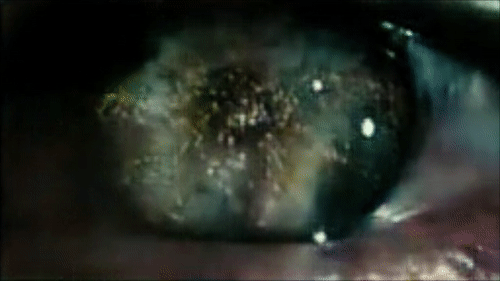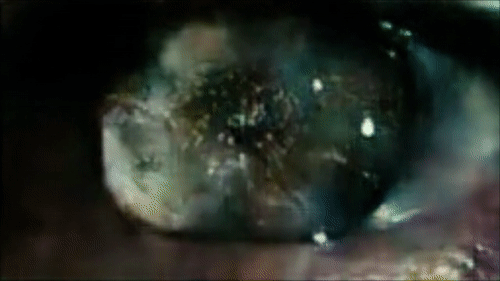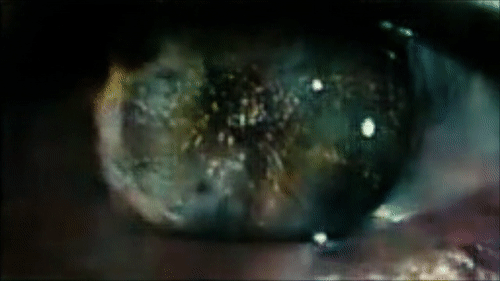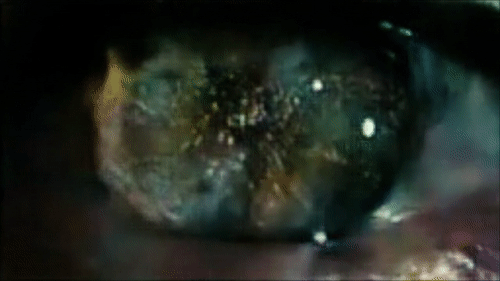
 Autoencoding Video Frames
Autoencoding Video Frames
No comments:
Post a Comment